

Reading, iterating and comparing two sorted files in java is a regular piece of code that most people would have encountered in their development journey. However, if the file size is very large typically in terms of millions of records, then this process can quickly become very time consuming. Here in this article, I talk about how we can make this entire process faster and time efficient by the use of java concurrency in practice.
Let’s consider two CSV files here that are being compared record by record. Let’s say one is an old file, and the other one is a new file. The new file has some changes, that we need to identify and only extract the changed records to a new file.

As you can see from the picture the records from the two CSV files. Record number two and three have been changed from previous to new file. Hence in order to compare and find the different in records we can make use of simple Java Iterator interface and compare the records line by line.
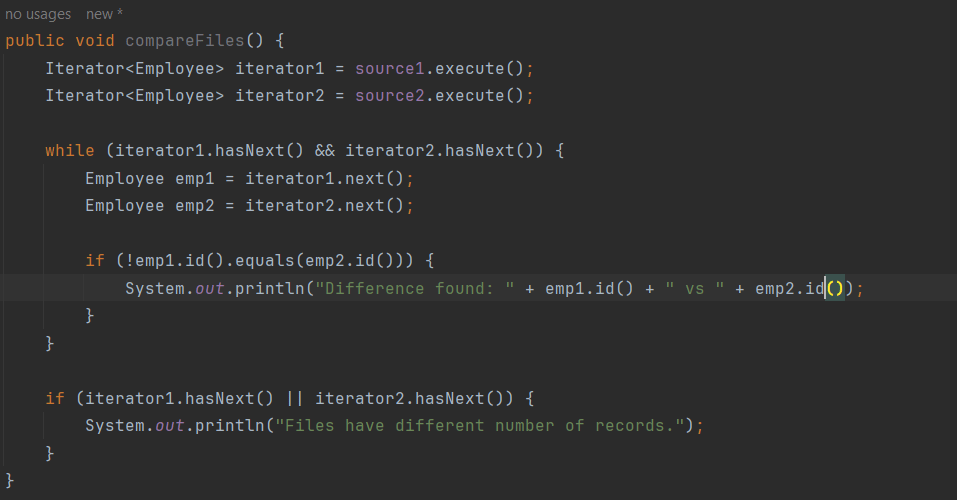
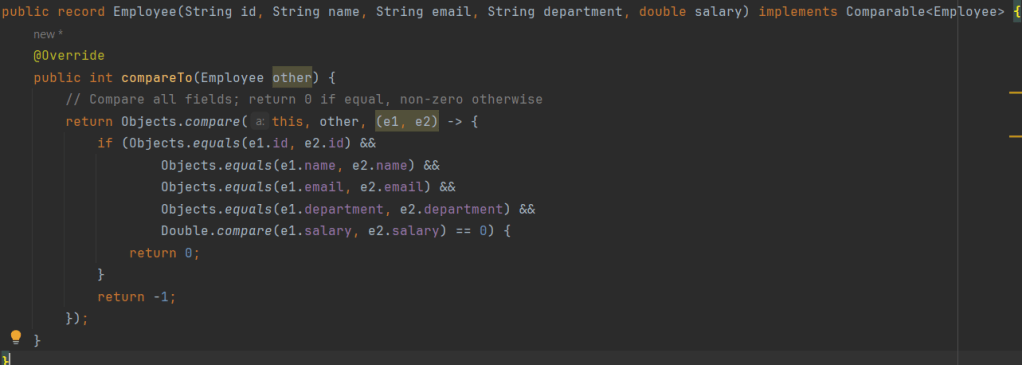
As we can see from the code, this shows a simple file compare, wherein the actual comparison is part of the Employee class which is a Record class that implements a Comparable
We implement file reader as an iterator and them pull out records and compare them one by one. CSVFileSource class implements the Source class and provides implementation of the execute method where it reads the file line by line, converts to Employee objects and returns as follows:

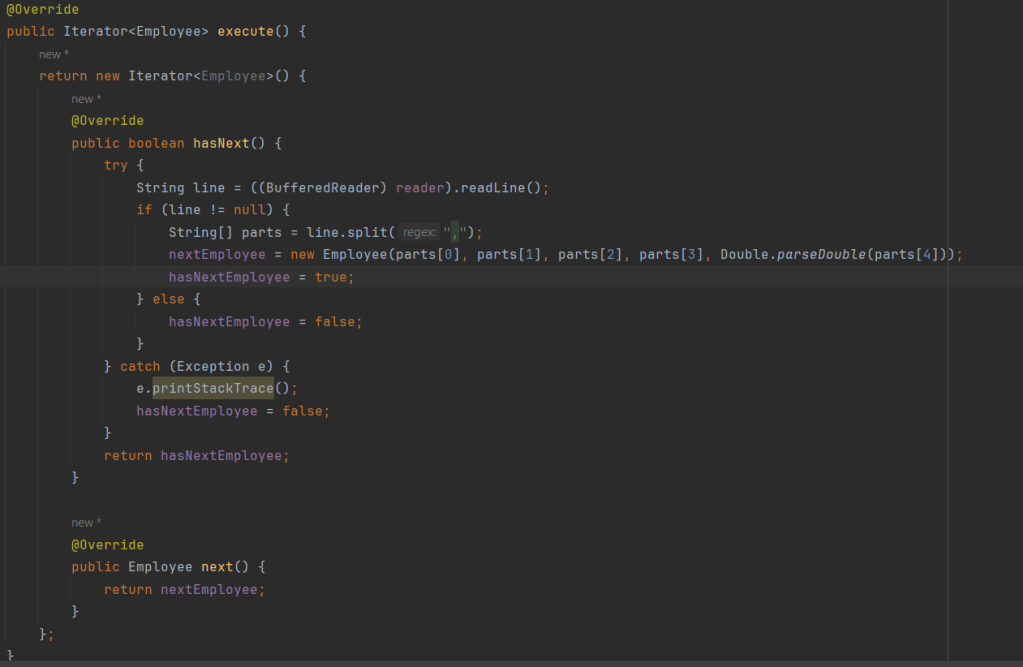
Using this simple piece of code we can compare 2 files line by line using the iterator pattern. Code for this entire functionality is available at github.com/SystemDesign.
In the next article we shall go a bit closer into how if the file size is large this entire process can take longer times to execute and how can leverage Java concurrency apis to bring down the overall time.
